What are ICEBERG tables?
Iceberg is an open table format that acts as a powerful metadata layer, offering reliable transactions, schema evolution, version history, and efficient data management for files within a data lake, even at a petabyte scale. Think of Iceberg as a bridge between storage (like Parquet files on S3) and compute platforms (such as Spark, Flink, Presto, Amazon Athena, Hive or BigQuery). With Iceberg, you define your table structure once at the API layer, allowing you to query the table from anywhere (like Snowflake, Spark, and more) without worrying about the physical location or partitioning of the data. The question is, why is this table format even needed? The reason is that traditional data lakes were associated with a number of limitations which made efficient data management difficult.
What were the problem with traditional data lakes?
The evolution of cloud-based Data Lakes has revolutionized how organizations manage and store their vast amounts of unstructured data. However, before the emergence of Data Lakes, traditional data warehouses faced several limitations that hindered efficient data management and processing. Similarly, while Data Lakes offer significant advantages, they also present challenges that stem from their design and architecture.
- Inconsistent Reads: Data lakes struggled with inconsistent reads, when dealing with a mix of batch and streaming data or appending new data. This inconsistency could lead to discrepancies in analytical insights derived from the data, affecting decision-making processes.
- Complex Data Modification: Fine-grained modification of existing data within data lakes could become complex, especially when organizations needed to comply with regulatory requirements such as GDPR. Ensuring compliance while making precise modifications to data records posed significant challenges.
- Performance Degradation: Traditional data lakes experienced performance degradation when handling millions of small files. This inefficiency resulted in increased latency and decreased throughput during data processing and analysis tasks, impacting overall system performance.
- Lack of ACID Transaction Support: Data lakes often lacked support for ACID transactions, essential for maintaining data integrity and ensuring reliable data operations. The absence of transactional guarantees could lead to data inconsistencies and compromise the reliability of the system.
- Limited Schema Enforcement/Evolution: Data lakes had limited capabilities for schema enforcement and evolution. Without robust schema management mechanisms, ensuring data consistency and compatibility across different data sources and applications was challenging, leading to data quality issues and compatibility concerns.
These limitations have underscored the need for a more flexible, scalable, and efficient data management solution. Apache Iceberg, with its innovative features and capabilities, addresses these challenges and provides a comprehensive solution for efficient data management and processing in modern Data Lake environments.
What are the main benefits and innovative features of ICEBERG Tables?
The table format brings a multitude of benefits and innovative features to the realm of modern data management. Let's go into some of the key advantages that ICEBERG Tables offer:
- Expressive SQL: ICEBERG Tables support expressive SQL queries, allowing users to harness the power of familiar SQL syntax for efficient data analysis and manipulation.
- Schema Evolution: The Tables facilitate seamless schema evolution, enabling organizations to adapt to changing data requirements without compromising data integrity or disrupting existing workflows.
- Partition Evolution - Hidden Partitioning: Introducing the concept of hidden partitioning by the tables, which enables efficient data organization and management without exposing the partitioning scheme externally, leading to improved performance and simplified data maintenance.
- Time Travel and Rollback - Data Versioning: ICEBERG Tables offer built-in support for time travel and rollback capabilities, allowing users to access historical versions of the data and revert to previous states. This feature is invaluable for auditing, debugging, and compliance purposes.
- Transactional Consistency - Data Consistency: ICEBERG Tables ensure transactional consistency, providing ACID compliance for data operations and maintaining data integrity across concurrent transactions. This guarantees reliable and predictable behavior, even in complex data processing scenarios.
- Engine Agnostic - Cross-platform Support: Offering engine agnostic architecture, ICEBERG Tables seamlessly integrate with diverse storage systems and query engines, allowing more flexibility and interoperability across different environments without vendor lock-in.
- Faster Querying - Pruning Metadata Files: ICEBERG Tables optimize query performance by pruning metadata files that are not needed for a particular query and filtering out data files that don’t contain matching data. This optimization minimizes data scanning and retrieval overhead, resulting in faster query execution and improved resource utilization.
How is that possible? - Understanding the technology powering ICEBERG tables
As Iceberg is a table format, it is important to define what a table format actually is.
What’s a Table Format?
Table formats serves as a way to organize a dataset’s files to present them as a single “table”. They enable multiple users and tools to interact with data simultaneously, simplifying data management processes. The primary goal of a table format is to provide the abstraction of a table to people and tools and allow them to efficiently interact with that table’s underlying data.
The Iceberg Table Format
Before delving into ICEBERG's architecture, it's essential to clarify its scope:

Iceberg Table’s Architecture
With the knowledge of the table format definition we can dive into the Architecture of Iceberg.

ICEBERG's architecture has three main layers:
- The ICEBERG Catalog:
Acts as a mapping mechanism for associating table names with their physical locations and supports atomic operations for updating referenced pointers. The first step for anyone looking to read the table is to find the location of the current metadata pointer. For example, in the diagram shown above, there are 2 metadata files. The value for the table’s current metadata pointer in the catalog is the location of the metadata file on the right with snapshot s1 in it. - The Metadata Layer:
Stores essential and enriching information about the constituent files for every different snapshot/transaction. The information within metadata files, manifest lists, and manifest files, provide comprehensive information about the dataset's structure, partitioning, and snapshots information.- Metadata File: The backbone of ICEBERG's metadata management system, containing vital information about the table's schema, partitioning scheme, and snapshots. Metadata files are stored separately from the data files, allowing for more efficient metadata storage.
- Manifest List: The manifest list has information about each manifest file that makes up the snapshot, such as the location of the manifest file, what snapshot it was added as part of, and information about the partitions it belongs to and the lower and upper bounds for partition columns for the data files it tracks.
- Manifest File: Tracks data files and offers additional metadata and statistics about each file, facilitating efficient data access and management. Each manifest file keeps track of a subset of the data files for parallelism and reuse efficiency at scale. They contain a lot of useful information that is used to improve efficiency and performance while reading the data from these data files, such as details about partition membership, record count, and lower and upper bounds of columns.
- The Data Layer: Contains the raw data files, including data stored in various formats such as Apache Parquet, CSV, and JSON.
When should you use ICEBERG Tables? (Use Case Scenarios)
Apache Iceberg is a versatile solution for modern data management requirements and offers a wide range of functions tailored to different project scenarios. Here's when you should consider leveraging ICEBERG Tables:
- Frequent Deletes: Ideal for tables requiring frequent deletions, such as enforcing data privacy laws.
- Record-Level Updates: Beneficial for tables needing frequent updates, enabling individual record modifications without dataset republishing.
- Unpredictable Changes (SCD): Suitable for tables with unpredictable changes, like Slowly Changing Dimension (SCD) tables, ensuring data consistency.
- Transactional Reliability: Iceberg ensures ACID transactions, making it suitable for transactions needing guaranteed data validity, durability, and reliability.
- Historical Data Analysis: Facilitates querying historical data versions for trend analysis, change analysis, or rollback, essential for understanding data evolution over time.
Comparison to other Table Format Solutions
Similar to the variety of file formats such as Parquet, ORC, Avro, and JSON, there exist alternatives to Iceberg that offer similar functionalities and benefits. One contender is the Delta Lake project developed by Databricks.
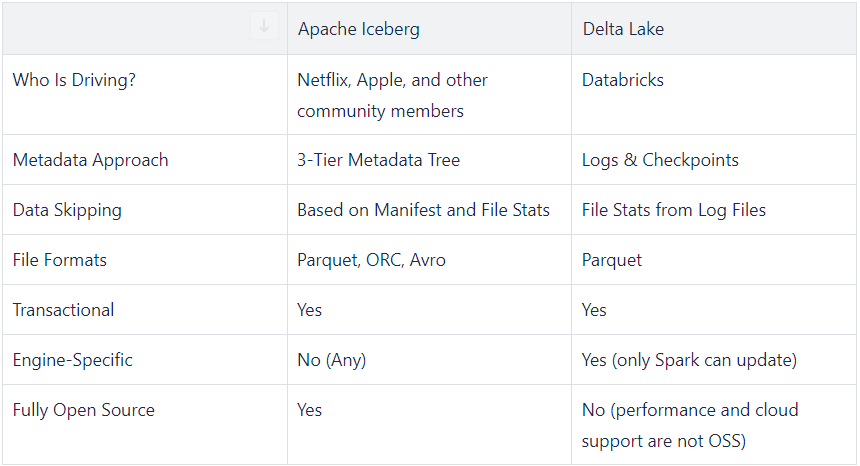
From a technical standpoint, Delta Lake shares some functionality with Iceberg, but notable differences exist. While Iceberg operates as an independently governed Apache project, driven by various industry players, Delta Lake is solely sponsored and controlled by Databricks. Moreover, Delta Lake is not entirely open source, as write operations are confined to Spark, and performance enhancements for reads are not open sourced. In contrast, Iceberg has a diverse community of contributors, including prominent names such as Netflix, Apple, Airbnb, Stripe, Expedia and Dremio.
Advantages of Iceberg Over Other Formats
Despite the availability of several table format options, Iceberg is characterized by several decisive advantages that are of a similar nature to previous open source projects such as Apache Parquet. One notable advantage is Iceberg's independence from a governance standpoint, allowing diverse organizations across industries to contribute to its development, fostering wider adoption and growth. Furthermore, Iceberg offers several practical benefits:
- Equal Access: All applications have equal access, and processing isn't reliant on any specific engine, granting organizations the flexibility to tailor their data lake as needed.
- Performance Optimization: Fast and cost-efficient data access is ensured by performance optimizations based on best practices.
- Storage Flexibility: Iceberg is storage-system agnostic with no file system dependencies, offering flexibility in selecting and migrating storage systems.
- Proven Success: Iceberg has a proven track record in large-scale production deployments, handling tens of petabytes and millions of partitions.
- Open Source: Iceberg is 100% open source and independently governed.
Apache Iceberg represents the logical next step in data lake management. Providing a range of advanced features such as columnar data representation, time travel capabilities and transactional data format, Iceberg enhances not only query performance but also streamlines data management processes and increases scalability. As a result of these strengths, Iceberg is rapidly gaining traction, simplifying data lake management and empowering organizations to harness the full potential of their data assets.